The Database Is Not an Implementation Detail




Databases are critical functions of most systems that are in use today. But there seems to be two schools of thought within the engineering community about databases:
One suggests that the database is the most important thing in the world. It is where the data lives. It is the ultimate source of truth: systems are built .
The other suggests that the database is a low-level mechanism to provide persistence functionality. Business logic lives in the code, and the database merely supplies data for the use case (that executes the actual business logic) and then writes it back.
Both proper database selection and good performance tuning and monitoring are critical processes in both of these approaches.


The database as a low-level persistence mechanism
Business logic should not be concerned with whether our systems are backed with Oracle or MySQL. Filesystem. Database. Network. Delivery mechanism. These are all the things that we’d like to see abstracted away in order to keep architecture as clean as possible.
The most commonly used architectures preach about this, in layered architecture we try to keep logic flow from top to bottom, in order not to leak low level details to high level policies. Hexagonal architecture tells us to keep infrastructure on the periphery and not couple it with business logic in the inner part. Even Uncle Bob preaches this approach. The database is a detail and the devil is in the detail.
Whether you agree with Uncle Bob or not, if you’re writing code that drives the business logic, you need to keep the database in mind when writing that code. In the following paragraphs I ’d like to point out a couple of traps to avoid in order to design better database-backed systems.
It’s a trap: Database details leaking into business logic
Have a look at this bit of pseudo code that demonstrates a naughty leak, when business logic becomes coupled to a specific database:


You may think that it’s not too bad as it is very straightforward and it doesn’t introduce any extra abstractions. And changing the actual database vendor would be a multi-day and multi-person effort anyway. So what’s wrong here?
It violates the DRY principle. Propagating this pattern throughout your code would mean that if you needed to change to a different library or database then you’d have to fix it in many different areas of your code.
It’s not clean — a high-level component is polluted by low-level details. It knows that we use MySQL. It would not work with Oracle,PostgreSQL OR MongoDB, but it should! Remember soft in software. It should be able to be changed easily.
It’s challenging to test — you could mock-out the
mysqldependency in order to unit test the business logic inside the service, but how would you write an integration test for the database code? Sure, you could test the query itself, but stringly-typed functions like this one are hard to reuse.
This is nothing new. It’s been solved many times. One elegant solution is usage of the Repository pattern as described in Eric Evan’s Domain Driven Design book. It would serve as a lovely solution to the problem above:

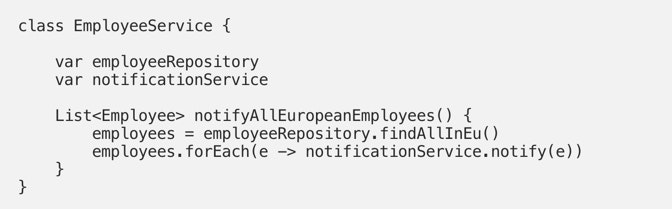
Low-level details don’t leak to high level policies anymore. The business logic is tidy and nicely isolated. You know that this is the correct approach (or to be more specific, one of many correct approaches), and now you could consistently use it across your codebase.
It’s a trap: Looping over entity graphs causing unwanted N+1 selects problem
Once you’ve abstracted away low-level details and hidden them behind appropriate patterns, you can start test-driving business logic with these patterns and stop worrying about specific queries. The idea of developing pure business logic against in-memory mocks is really tempting, but don’t get dragged too far away from reality.
Yes, it is true that using in-memory mocks increases development velocity as the tests run faster and you don’t need to wait for all the infrastructure to be set up and used (like a real database). However you must also take into account that in-memory mocks have disadvantages — look at this code from Uncle Bob. It’s a simple foreach loop over an entity graph loading other entities.


Unless he’d make sure to model the entities using JOINs to build the graph in a single query, he’d have an N+1 selects problem (a common anti-pattern that can seriously harm performance) in that particular piece of code. And that’s not even the worst thing. The worst thing is that this would work in production, but it would perform poorly. Code like this is tough to catch during testing phase and you’d need to use a profiler or verify exact amount of selects.
It’s a trap: Entities mirroring all table columns all the time
Many have been lured by the attractive promises of ORM frameworks which allow you to map entities fully and never worry about writing custom SQL. It’s supposed to sync auto-magically!
Please don’t default to this approach without some extra thinking. I’d like to demonstrate my point with a following example. Think of following user database table:


It’s tempting to map all the columns and all the relations to one nice rich entity and refer to it anytime you need. But it comes at potential performance price that may be too high for some systems.

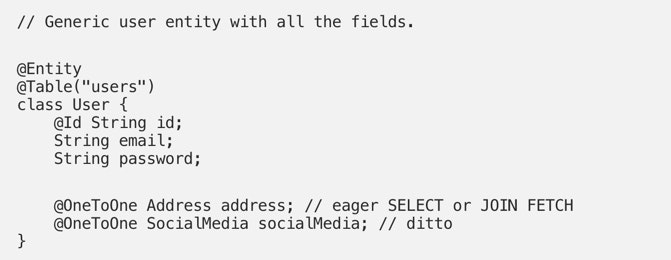
Consider two following scenarios:
Log in — you only care about the credentials (email, password) and you want a piece of logic that is able to check that the credentials are valid. Joining addresses or social media details would be extra unnecessary joins that’d slow down the functionality.
Present user details on a profile page — you don’t really want this code to depend on password-checking functionality or know anything about columns that are not going to be displayed on the UI. It’d violate the Single Responsibility Principle if these were included in the model.
Using one large entity per table is going to be mostly fine for smaller tables and/or more trivial uses cases, but for the requirements above you could split the large entity into two smaller and more focused entities like so (Java/JPA):


So is the database an implementation detail?
While my tips from above aren’t a comprehensive guide to designing performant database applications, I hope it’s clear by now that I don’t think that database is a mere detail. There is so much more to be learned about designing performant applications that use a database. I highly recommend the book High-Performance Java persistence where the author shares useful examples, tips, and tricks for writing performant real-world applications.
Final thoughts
What about you? I hope that you’ll strive to hide databases behind nice abstractions and make it nearly invisible to the system, I hope you will keep some database fundamentals in mind while doing that. I’d love to hear your thoughts and ideas on what I’ve covered today!
Michal Vrtiak
Michal Vrtiak is a Java Engineer at Help Scout, where we make excellent customer service achievable for companies of all sizes.