Testing Code That Talks to the Database



In my previous blog post we talked about working with databases and how crucial they are in the design of a well functioning system. One of the things mentioned was the usage of Repository pattern and how can it help us to design clean systems.
As a quick reminder, let’s bring up the Repository pattern definition from the famous Domain Driven Design book:
It acts like a collection, except with more elaborate querying capability. Objects of the appropriate type are added and removed, and the machinery behind the REPOSITORY inserts them or deletes them from the database.
Different projects, libraries, and people interpret this pattern slightly differently — some focus on its generic collection-like interface, other enrich it with finer-grained functions specific to a certain domain problem. Some prefer using Data Access Objects or Data Access Layer, that share plenty of common characteristics of repositories.
For the purpose of this post I’d like to put these differences aside and focus on what is common —database access via a high level repository-like component. How do we test a component like this?


Unit testing repositories
As a TDD practitioner, I acknowledge tests to be one of the most powerful tools available in order to produce well-designed systems. I personally tend to prefer plain old unit tests with no dependencies and no I/O access, as they’re faster to run and there is no extra overhead needed in order to understand a single piece of tested functionality. Are unit tests a good fit for testing repositories?
Let’s consider the following repository interface and its implementation class:



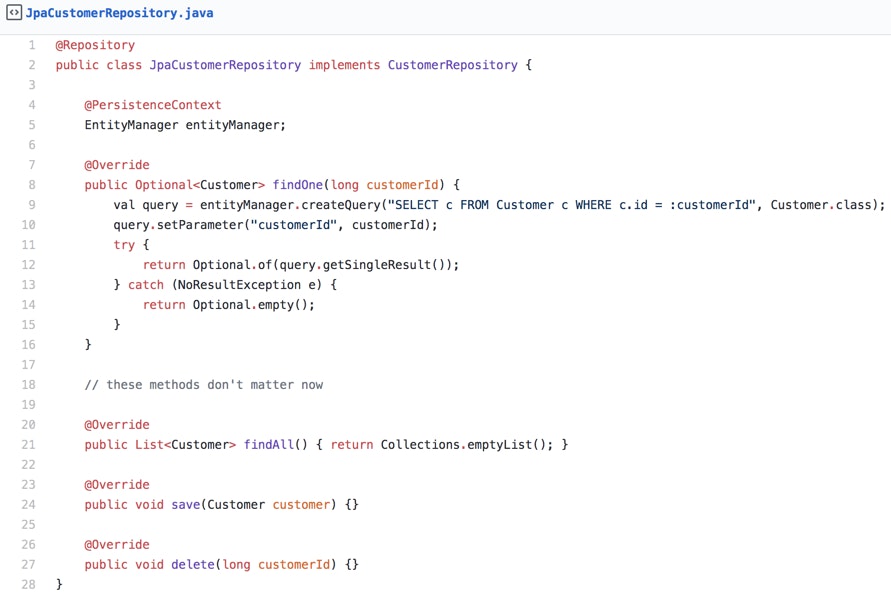
Now let’s focus on the findOne function. How could we design a unit test for code like that? Perhaps we’d end up with something like this:

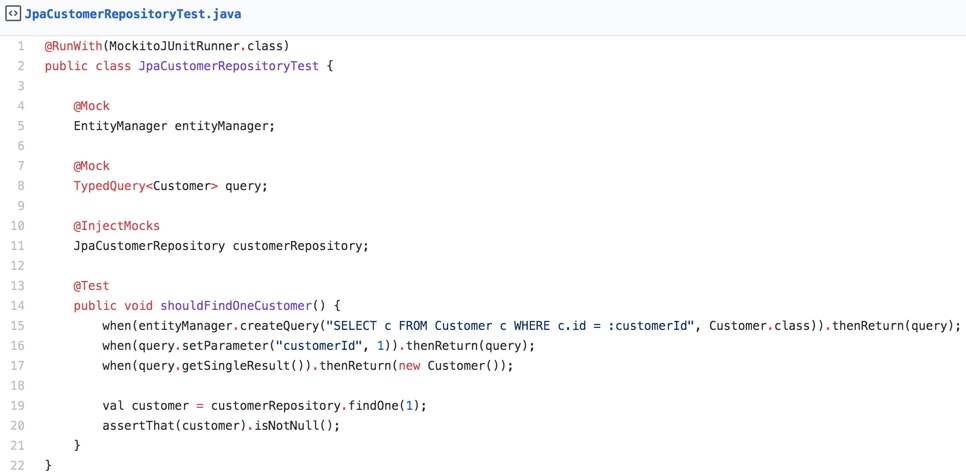
How useful is that? I reckon not very much. The test basically asserts that the query made it all the way to the database, but that’s it. I see several issues with the test above that make it of very little to no value:
there is no conditional logic tested, just boilerplate
hard to test database-to-object mapping layer if we don’t know how exactly will the returned data look like (think of timestamps, BLOBs etc.)
we don’t know the efficiency of the query
we don’t know if we’re targeting the right data sets with the query
We can clearly see that there are some major challenges with tests like these and mocking the database out gives us only little value.
What does a meaningful repository test look like?
A meaningful test should address all the issues listed above. In order to fully test the database communication across all layers (querying, mapping, I/O etc.) it’s best to use the actual database, as none of these concerns has to be mocked out anymore. Before we do that we have to ask ourselves a couple of questions:
Does the database play a significant role in our system that is worth adding setup complexity to the test suite?
Do we ever execute non-trivial queries that deserve to be properly tested?
If we use a Continuous Integration server, are we ready to level up our setup by adding a database?
There are plenty of systems that do use a database, but it isn’t a central component, so perhaps all of this isn’t worth the hassle. Another good compromise could be using a substitute — a simpler in-memory database for the tests, like HSQLDB for example.
There are systems where the database is the crucial component and not merely an implementation detail. Let’s have a look on how could we achieve such meaningfulness by using an actual database:

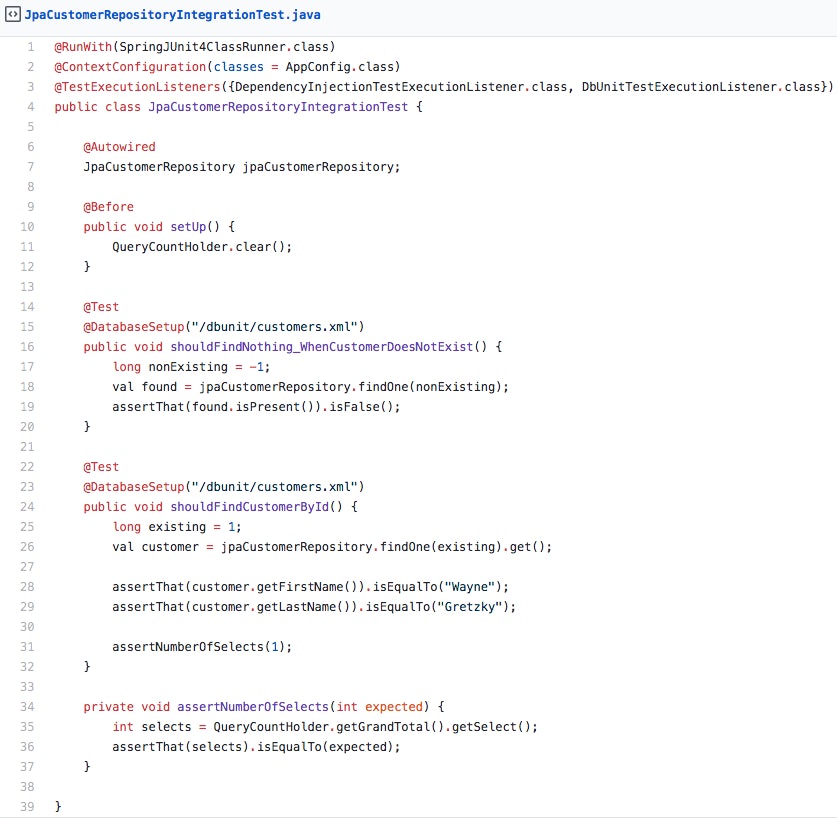
What’s going on in this test? It works like this:
It establishes a database connection prior to executing any test methods by using a Spring text execution listener —
DbUnitTestExecutionListenerIt populates the database to a known state using fixture data — see
@DatabaseSetupannotation, that is backed by the DbUnit libraryIt executes the query against the actual database
It inspects the result data which have been processed by an appropriate database-to-object mapping layer
It verifies that expected amount of SQL DML statements were executed
Is this still a unit test? No it isn’t — we needed to bootstrap all the database code. But it adds much more value, so I consider it meaningful.
Tips for writing meaningful repository tests
I’ve been writing test code in Java for repositories using a variety of databases (MySQL, Oracle, MS SQL Sever), libraries, and frameworks. It has taken plenty of mistakes, unstable tests, and head scratches to settle for what I call meaningful repository tests. In this section I’d like to share a few tips that have helped me to achieve this.
Simplify data fixture bootstrapping
There are two ways of bootstrapping data fixtures for a repository test:
Build an in-memory object model and let your application services persist it
Populate the database with a set of known fixture data
While the first solution may seem tempting, I strongly suggest avoiding it. Why? Let’s have a look at the two following code samples:



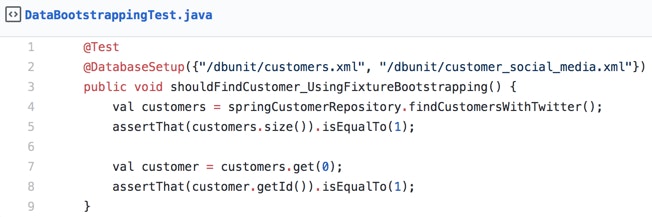
The first one is so much more verbose than the latter one. It will be cumbersome to maintain, and it is harder to reason about in general, simply because of its size. The second one will make you to navigate to a fixture file (XML in this case, but it can be a simple SQL script as well), but the test remains very clean and un-bloated.
Avoid boilerplate
If we find ourselves copy/pasting similarly looking code any time we want to add a new repository method, then it’s wise to abstract as much of this boilerplate away as possible. Such boilerplate may look like this (example using JPA):


We should try to push hard and keep simplifying this code until we’ll end up with the only important bit — the query (SQL, JPQL, HQL, Criteria object, etc.). I prefer using Spring Data project for its simplicity. A good boilerplate-free repository method may look like this:

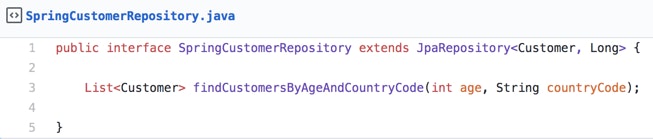
There is no way for this component to do anything else, as it only is an interface (the SQL string is calculated from the method name or using a single @Query annotation). With code like this we can ignore all the low-level mechanics under the hood, and only focus on the high level query definition.
Use query builders only as a last-resort solution
Query builders seem to be fairly popular amongst developers. They’re easy to develop and very easy to extend. They’re even testable; you can test that a particular combination of parameters ends up in a particular query.
What’s wrong with query builders then? Everything we mentioned above. We’d be unit-testing that the right query makes it to the database, but this isn’t the meaningful test we’re looking for. In order to write a meaningful test for a method using a query builder, we need to test all of the permutations. This results in cumbersome tests, odd naming, and hard-to-reason about code.
That being said, there are some good use cases for query builders (when the number of query parameters is too high or the rules are too complex), and some elegant libraries which make query builders a bit easier to use, but they should not be the default tool to use. Imagine a case of emergency. Which code would you rather reason about?

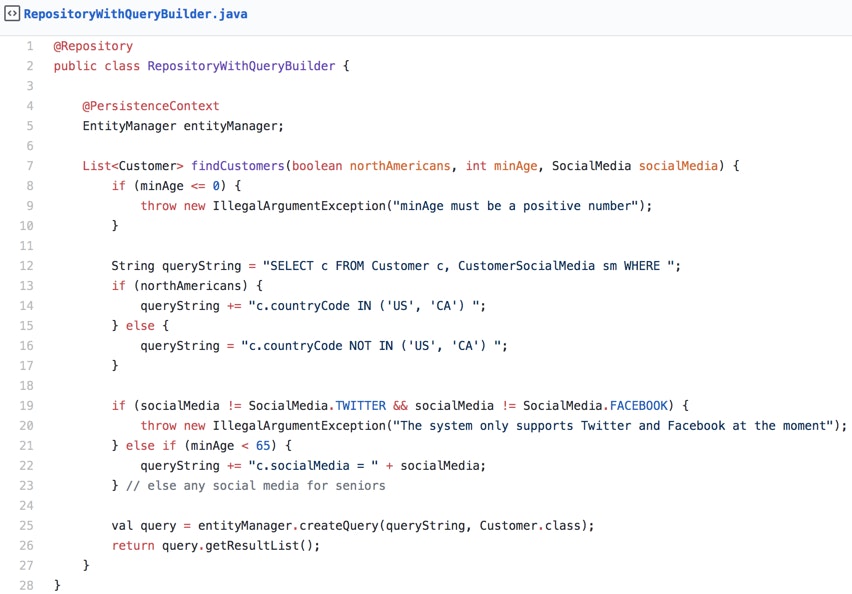


I’ll let you draw your own conclusions from the examples above. Remember that considered and calculated verbosity can actually be an overall win for your code.
Keep repositories pure (no conditional logic)
The simpler the repository, the more straightforward to test it is. We’ve talked about avoiding boilerplate a couple of paragraphs above. Putting any conditional logic, or any logic different than mere query delegation into the repository, will result into a couple of drawbacks:
potential need for multiple test types (a unit test for the conditional logic and an integration test for database interaction)
harder to reason about final query sent to the database
violation of Single Responsibility Principle
Keep your repositories pure. A repository should be concerned with data access only (using a well-defined interface). Any conditional logic important for a given use case (if-ing, looping, transforming etc.) belongs elsewhere, be it a service-layer component, an entity, or another domain component.
Assert statement count
Measuring performance of database queries is an important concern that we should address on our production servers using appropriate technologies. Should the tests be concerned as well? Perhaps in the ideal world, but I don’t consider that very realistic. We’d need to test using production-like data volume and traffic, which is very challenging to set up in an isolated environment.
Still, there is something we can easily do — asserting counts of SQL statements sent to the database.
The following code exercises a repository method and asserts that 2 SQL SELECT statements were performed (we achieved that by using a nice little datasource-proxy library):

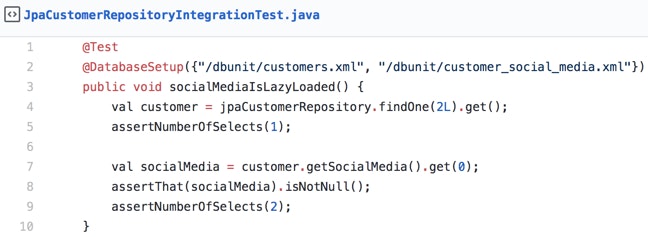
This can be fairly useful in case we’re using an ORM tool that takes care of query generation for us. With assertions like these we would be able to identify any unwanted interactions (cascade updates/deletes for example) or we could easily prevent a well-known and feared N+1 Selects problem.
Summary
We’ve looked into talking to database using a repository pattern and we thought about writing meaningful tests that will give us certainty that our database code works across all layers, and we will feel much more confident about any future changes.
I tried to give you some tips I learned on my way designing variety of database-systems. I’d love to hear about your experience if you’ve been running into similar challenges or if this post has inspired you into improving your current tests!
See the code samples here.
Michal Vrtiak
Michal Vrtiak is a Java Engineer at Help Scout, where we make excellent customer service achievable for companies of all sizes.